The Qwen3-30B-A3B-Instruct-2507 (UD-Q4_K_XL) is a 30.5-billion-parameter Mixture-of-Experts (MoE) model that activates roughly 3.3 billion parameters per token. It supports extended context lengths of up to 256K tokens and is optimized for instruction following, reasoning, and long-document understanding. This analysis examines the economics of running the model on self-hosted cloud GPUs—focusing on NVIDIA A10 instances—versus managed API providers that charge per token. The goal is simple: quantify the actual cost of deployment under realistic throughput and reliability requirements.
Understanding the Model
Because Qwen3-30B-A3B is a Mixture-of-Experts, it only activates a subset of experts per token. This architecture reduces compute requirements compared to a fully dense 30B model while maintaining strong reasoning ability. The UD-Q4_K_XL quantization format further compresses memory usage and reduces bandwidth demand, enabling the model to run efficiently on commodity GPUs. A single NVIDIA A10 with 24 GB VRAM is capable of handling this setup, including room for KV cache under typical batch sizes. While high-end GPUs, such as the A100 or H100, still dominate for extreme batch throughput and ultra-long contexts, the A10 provides the best price-to-performance balance for this quantized MoE configuration, making it a rational choice for deployment.
Self-Hosted Cloud Deployment
Running Qwen3-30B-A3B on your own cloud GPUs comes with both flexibility and responsibility. The cost extends beyond the raw hourly rate—you must also manage autoscaling, monitoring, failover, runtime patching, and performance tuning. When executed well, with efficient batching, optimized tokenization, and minimal idle time, the effective cost per token can be significantly lower than API alternatives. Poor utilization, however, erases those savings and can result in higher fees than managed services.
| Provider / Source | Price per Hour (USD) |
|---|---|
| Modal (serverless) | $1.10 |
| Lambda.AI (on-demand) | $0.75 |
| Low-end market (rare) | $0.17 |
| AWS EC2 g5.xlarge (1× A10G, on-demand) | $1.006 |
| Azure NV6ads A10 v5 (on-demand) | $0.73 |
| Oracle Cloud (A10, on-demand) | $2.00 |
Managed Service Alternative
Managed services offer simplicity. Providers handle scaling, high availability, and security while exposing Qwen3-30B variants via APIs with set context limits and per-token pricing. This shifts operational burden away from the user but comes with higher per-token costs and less control over performance optimization.
| Provider | Variant(s) surfaced | Max context | Pricing (per 1M tokens) |
|---|---|---|---|
| DeepInfra | Qwen3-30B-A3B (base) | 40,960 | $0.29 |
| SiliconFlow | Qwen3-30B-A3B (base) | 131K | $0.45 |
| Novita.ai | qwen/qwen3-30b-a3b-fp8 | 40,960 | $0.45 |
| Fireworks AI | Qwen3-30B-A3B | 131,072 | $0.60 |
Comparing Costs
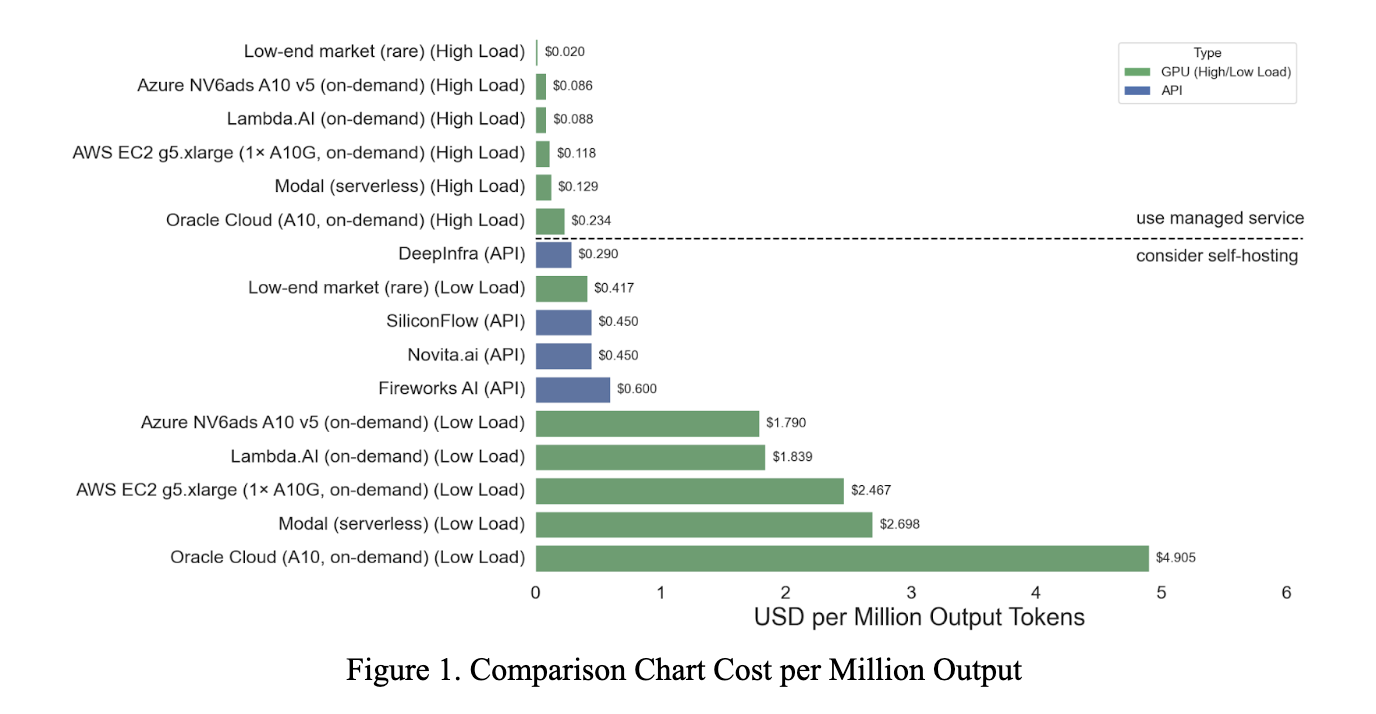
The economics of deployment hinge on utilization. When GPUs are fully loaded—about 2,370 tokens per second on an A10—the cost per million tokens is highly competitive. At high load, fees range from $0.020/M for rare low-end markets to $0.234/M for Oracle. Standard options such as Azure ($0.086/M), Lambda ($0.088/M), and AWS g5.xlarge ($0.118/M) undercut API prices by significant margins, often 3–7× cheaper than managed providers. Even Oracle, despite its higher hourly rate, remains less expensive than any API offering when utilization is high.
At low utilization—around 113 tokens per second—the equation reverses. Costs soar to between $0.417/M and $4.905/M depending on the cloud. Only the rare low-end $0.417/M quote competes with API pricing, edging out SiliconFlow and Novita, but still more expensive than DeepInfra. More mainstream clouds, such as Azure at $ 1.79/M or AWS at $ 2.47/M, are multiples more costly than managed services. In these scenarios, APIs dominate in price because they abstract away idle GPU time.
Conclusion
The decision between self-hosting and managed services is ultimately a question of utilization. If you can consistently keep GPUs saturated, self-hosting on A10 instances provides a clear economic advantage, often cutting costs by 3–7× compared to APIs. However, if workloads are spiky, unpredictable, or low-volume, managed services win decisively, offering lower effective costs along with operational simplicity. In practice, many teams may find a hybrid strategy attractive: rely on self-hosted A10s for sustained, high-throughput jobs and leverage APIs for overflow or irregular workloads. The takeaway is straightforward—efficiency is the real currency in model deployment, and whichever path you choose, utilization will determine whether you save money or lose it.